
数据结构基础
1 数据结构分类
线性结构:把所有节点用一根线串起来
顺序表与链表
非线性结构
树与图
2 线性结构
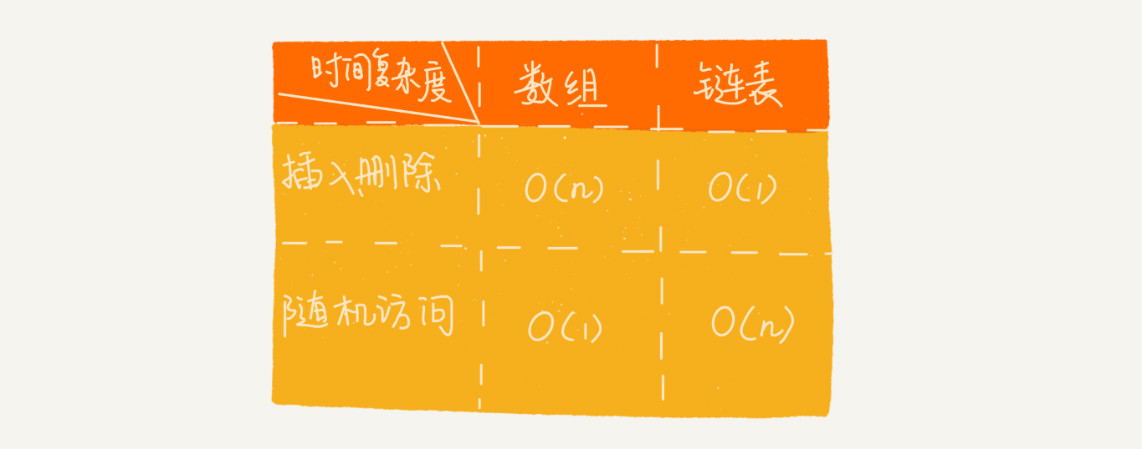
顺序表与链表的区别
顺序表需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个 100MB 大小的顺序表,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于 100MB,仍然会申请失败。 而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用,所以如果我们申请的是 100MB 大小的链表,根本不会有问题。

连续存储(顺序表)
对于顺序表来说,是要开辟一个连续的内存空间
假设有一个顺序表[1,2,3,4],其起始地址为1000(如上图),要找到第三个元素(下标为2),表达式为:第三个元素的起始地址为:1000+(2*4)
在python中列表就是一种顺序表,它提供了哪些操作?
对于这些操作的时间复杂度是多少?
比如,
找到下标为n的元素,其时间复杂度为:O(1)
增删改来说,其时间复杂度就为:O(n)(是一种连续的空间,增删改都会使其它元素地址发生改变)
为啥顺序表(列表)的索引或者下标是从0开始的?
假设是从1开始的,找到上面第三个元素(下标为3),表达式为:1000+(4*(3-1)),相比于下标为0开始,多做了一次运算
关于顺序表的优缺点
- 优点:
- 存取速度快
- 缺点:
-
事先需要知道数组的长度
-
需要大块的连续内存
-
插入删除非常的慢,效率极低
离散存储(链表)
定义:
1.n个节点离散分配
2.通过指针相互关联
关于链表的优缺点
空间没有限制,插入删除元素很快
查询比较慢
链表的节点的结构如下

data为自定义的数据,next为下一个节点的地址。
链表的分类
单向链表
双向链表
循环链表
链表实现
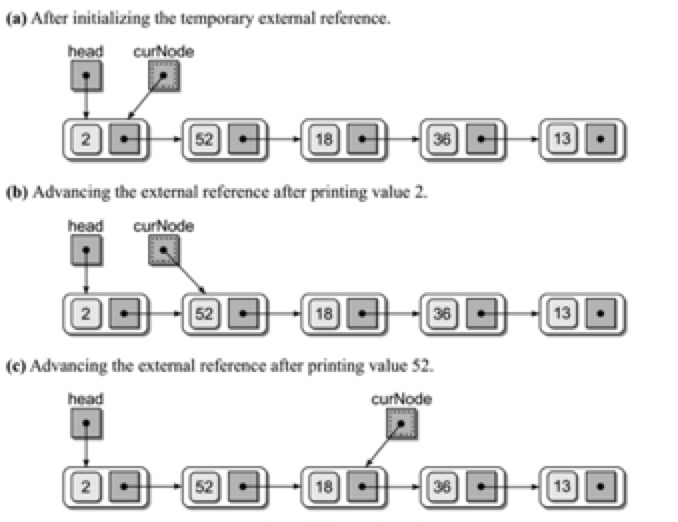
在python中没有指针的概念,我们使用类来实现链表


# 单链表的实现 class Node(): def __init__(self, ele): self.ele = ele self.next = None class SingleLinkList: def __init__(self, node=None): # 指向头部节点 self.__head = node def is_empty(self): """ 判断链表是否为空 :return: bool """ return not self.__head def length(self): """ 返回列表长度 :return: int """ cur = self.__head ctn = 0 while cur is not None: ctn += 1 cur = cur.next return ctn def travel(self): """ 遍历链表 :return: val """ cur = self.__head while cur is not None: print(cur.ele, end=" ") cur = cur.next print("--") def append(self, ele): """在末尾添加元素""" node = Node(ele) if self.is_empty(): self.__head = node else: cur = self.__head while cur.next is not None: cur = cur.next cur.next = node def add(self, item): """在头部添加元素""" node = Node(item) node.next = self.__head self.__head = node def remove(self, item): """ 删除指定元素 :param item: :return: """ pre = None cur = self.__head while cur is not None: if cur.ele == item: if pre is None: self.__head = cur.next else: pre.next = cur.next break else: pre = cur cur = cur.next def search(self, item): """检索检点是否存在""" cur = self.__head while cur is not None: if cur.ele == item: return True else: cur = cur.next return False def insert(self, pos, item): """ 在指定位置插入元素 :param pos: :param item: :return: """ if pos <= 0: self.add(item) elif pos >= self.length(): self.append(item) else: ctn = 0 cur = self.__head while ctn < pos - 1: ctn += 1 cur = cur.next node = Node(item) node.next = cur.next cur.next = node if __name__ == '__main__': ll = SingleLinkList() ll.append(1) ll.append(2) # ll.append(3) ll.travel() ll.remove(1) ll.travel()
# 单向循环链表实现 class Node(): def __init__(self, ele): self.ele = ele self.next = None class SingleLinkList: def __init__(self, node=None): # 指向头部节点 self.__head = node if node: node.next = node def is_empty(self): return not self.__head def length(self): cur = self.__head if self.is_empty(): return 0 ctn = 1 while cur.next != self.__head: ctn += 1 cur = cur.next return ctn def travel(self): """ 遍历链表 :return: val """ if self.is_empty(): return False cur = self.__head while cur.next != self.__head: print(cur.ele, end=" ") cur = cur.next print(cur.ele) def append(self, ele): """在末尾添加元素""" node = Node(ele) if self.is_empty(): self.__head = node node.next = node else: cur = self.__head while cur.next != self.__head: cur = cur.next cur.next = node node.next = self.__head def add(self, item): """在头部添加元素""" node = Node(item) if self.is_empty(): node.next = node self.__head = node else: cur = self.__head while cur.next != self.__head: cur = cur.next node.next = self.__head self.__head = node cur.next = self.__head def remove(self, item): pre = None cur = self.__head if self.is_empty(): return while cur.next != self.__head: if cur.ele == item: # 头节点 if cur == self.__head: rear = self.__head # 得到尾结点 while rear.next != self.__head: rear = rear.next self.__head = cur.next rear.next = self.__head # 中间节点 else: pre.next = cur.next return else: pre = cur cur = cur.next # 最后一个节点 if cur.ele == item: if cur.next == cur: self.__head = None else: pre.next = self.__head def search(self, item): """检索检点是否存在""" cur = self.__head while cur.next != self.__head: if cur.ele == item: return True else: cur = cur.next return False def insert(self, pos, item): if pos <= 0: self.add(item) elif pos >= self.length(): self.append(item) else: ctn = 0 pre = self.__head while ctn < pos - 1: ctn += 1 pre = pre.next node = Node(item) node.next = pre.next pre.next = node if __name__ == '__main__': ll = SingleLinkList() ll.insert(0,1) ll.travel()
# 双链表的实现 from single_link import SingleLinkList class Node(): def __init__(self, ele): self.ele = ele self.pre = None self.next = None class DoubleLinkList(SingleLinkList): def append(self, ele): """在末尾添加元素""" node = Node(ele) if self.is_empty(): self._SingleLinkList__head = node else: cur = self._SingleLinkList__head while cur.next is not None: cur = cur.next cur.next = node node.pre = cur def add(self, item): """在头部添加元素""" node = Node(item) node.next = self._SingleLinkList__head if not self.is_empty(): self._SingleLinkList__head.pre = node self._SingleLinkList__head = node def remove(self, item): cur = self._SingleLinkList__head while cur is not None: if cur.ele == item: # 判断是否为头节点 if cur == self._SingleLinkList__head: self._SingleLinkList__head = cur.next # 判断是否只有一个节点 if cur.next: cur.next.pre = None else: cur.pre.next = cur.next # 判断是否为尾结点 if cur.next: cur.next.pre = cur.pre break else: cur = cur.next def insert(self, pos, item): if pos <= 0: self.add(item) elif pos >= self.length(): self.append(item) else: ctn = 0 cur = self._SingleLinkList__head while ctn < pos - 1: ctn += 1 cur = cur.next node = Node(item) node.next = cur.next node.pre = cur cur.next = node if cur.next: cur.next.pre = node if __name__ == '__main__': ll = DoubleLinkList()
约瑟夫问题
设编号为1,2,… n的n个人围坐一圈,约定编号为k(1<=k<=n)的人从1开始报数,数到m 的那个人出列,它的下一位又从1开始报数,数到m的那个人又出列,依次类推,直到所有人出列为止,求出队列中最后的一个人或者出队编号的序列
class Node: def __init__(self, ele): self.ele = ele self.next = None class SingleLinkList: def __init__(self, node=None): self.__head = node if node: node.next = node def length(self): cur = self.__head if self.is_empty(): return 0 ctn = 1 while cur.next != self.__head: ctn += 1 cur = cur.next return ctn def is_empty(self): return not self.__head def append(self, ele): node = Node(ele) if self.is_empty(): self.__head = node node.next = node else: cur = self.__head while cur.next != self.__head: cur = cur.next cur.next = node node.next = self.__head def travel(self): if self.is_empty(): return False cur = self.__head while cur.next != self.__head: print(cur.ele, end=" ") cur = cur.next print(cur.ele) def find_ele(self, num, station=1): while station > 1: self.__head = self.__head.next station -= 1 first = None second = self.__head while self.length() != 1: print("当前链表值:", end="") self.travel() print("链表长度:", self.length()) ctn = 1 while ctn < num: first = second second = second.next ctn += 1 print("删除的元素是:", second.ele) if self.__head.ele == second.ele: self.__head = second.next first.next = second.next second = second.next if __name__ == '__main__': obj = SingleLinkList() for i in range(1, 101): obj.append(i) obj.find_ele(150, 20) print("最后的孩子:", end="") obj.travel()
class Child(object): first = None def __init__(self, no = None, pNext = None): self.no = no self.pNext = pNext def addChild(self, n=4): cur = None for i in range(n): child = Child(i + 1) if i == 0: self.first = child self.first.pNext = child cur = self.first else: cur.pNext = child child.pNext = self.first cur = cur.pNext def showChild(self): cur = self.first while cur.pNext != self.first: print("小孩的编号是:%d" % cur.no) cur = cur.pNext print("小孩的编号是: %d" % cur.no) def countChild(self, m, k): tail = self.first while tail.pNext != self.first: tail = tail.pNext # 出来后,已经是在first前面 # 从第几个人开始数 for i in range(k-1): tail = tail.pNext self.first = self.first.pNext # 数两下,就是让first和tail移动一次 # 数三下,就是让first和tail移动两次 while tail != self.first: # 当tail == first 说明只剩一个人 for i in range(m-1): tail = tail.pNext self.first = self.first.pNext self.first = self.first.pNext tail.pNext = self.first print("最后留在圈圈中的人是:%d" % tail.no) c = Child() c.addChild(100) c.showChild() # 次数,第几个开始 c.countChild(150,20)
2.1 顺序表和链表的对比
一种可以实现“先进后出”的存储结构
栈类似于一个箱子,先放进去的书,最后才能取出来,同理,后放进去的书,先取出来
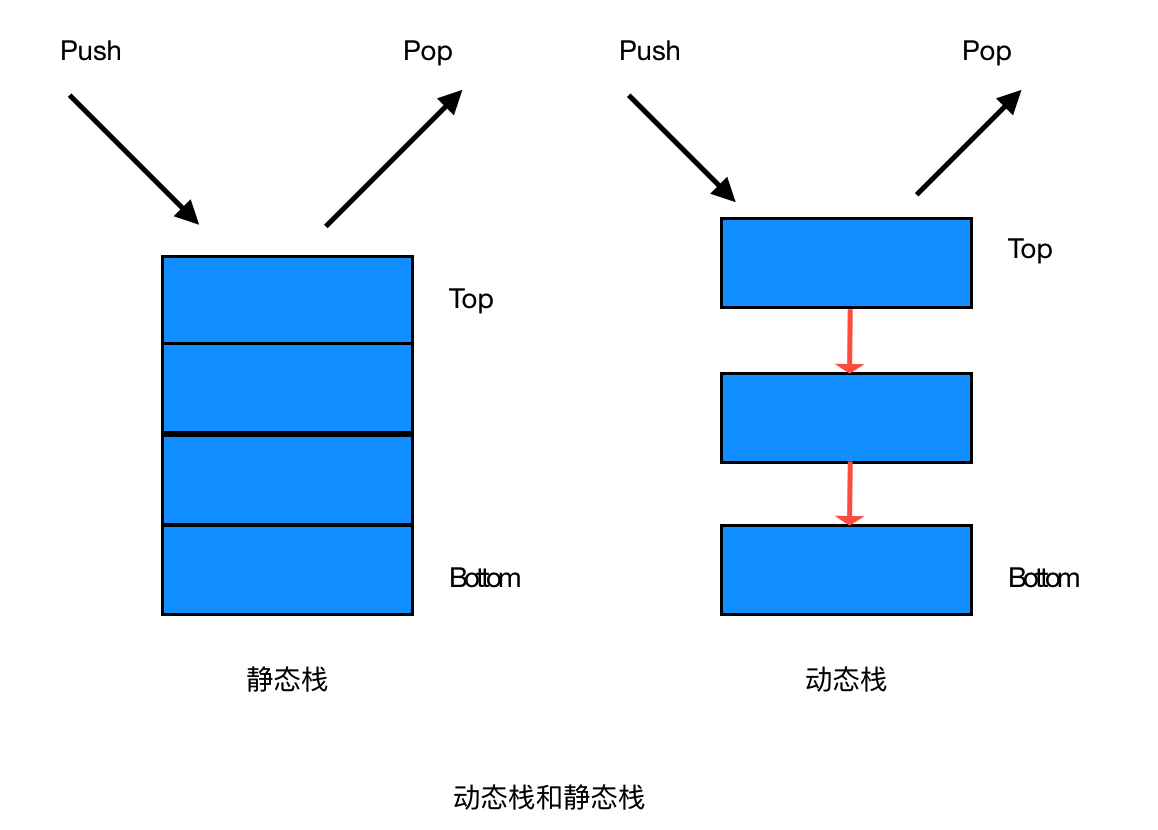
栈的分类
静态栈
静态栈的核心是数组,类似于一个连续内存的数组,我们只能操作其栈顶元素
动态栈
动态栈的核心是链表
栈的算法
栈的算法主要是压栈和出栈两种操作的算法,下面我就用代码来实现一个简单的栈。
首先要明白以下思路:
- 栈操作的是一个一个节点
- 栈本身也是一种存储的数据结构
- 栈有
初始化、压栈、出栈、判空、遍历、清空等主要方法
# 栈的实现 class Stack: """基于顺序表实现""" def __init__(self): self.__list = [] def push(self, item): # 时间复杂度O(1) self.__list.append(item) # 时间复杂度O(n) # self.__list.insert(0,item) def pop(self): # 时间复杂度O(1) return self.__list.pop() # 时间复杂度O(n) # return self.__list.pop(0) def peek(self): if self.is_empty(): return None return self.__list[-1] def is_empty(self): return not self.__list def size(self): return len(self.__list) if __name__ == '__main__': stack_obj = Stack() stack_obj.push(1) stack_obj.push(2) stack_obj.push(3) print("empty:", stack_obj.is_empty()) print("size:", stack_obj.size()) print(stack_obj.pop()) print(stack_obj.pop()) print(stack_obj.pop())
栈的实现
- 函数调用
- 浏览器的前进或者后退
- 表达式求值
- 内存分配...
def f1(): print("f1") f2() def f2(): print("f2") f3() def f3(): print("f3") f1() # 对于这个程序来说 执行函数f1,将f1压栈,打印"f1",执行f2,将f2压栈并将控制权交予f2,打印"f2",执行f3,将f3进行压栈并将控制权交予f3,打印"f3",出栈,则为f3先出
通过两个栈之间的入栈和出栈实现浏览器的前进和后退
# 对于表达式:8+5*4-3 分为操作符栈和数据栈 先将数值8和5放入数据栈,+号放入操作符栈,然后将4放入数据栈,由于乘号的优先级大于加号,继续将*号放入操作符栈,随后由于-号的优先级小于乘号,所以先将5*4计算并将结果放入数据栈,-号再放入操作符栈 # 注意:操作符放入的条件是,优先级大于栈顶的操作符优先级
2.3 线性结构的两种应用方式之队列
定义
一种可以实现“先进先出”的数据结构
队列的分类
静态队列和链式队列
队列的算法
# 队列的实现 class Queue: """基于顺序表""" def __init__(self): self.__list = [] def enqueue(self, item): # O(1) self.__list.append(item) # O(n) # self.__list.insert(0, item) def dequeue(self): # O(n) return self.__list.pop(0) # O(1) # return self.__list.pop() def is_empty(self): return not self.__list def size(self): return len(self.__list) if __name__ == '__main__': queue_obj = Queue() queue_obj.enqueue(1) queue_obj.enqueue(2) queue_obj.enqueue(3) print("empty:", queue_obj.is_empty()) print("size:", queue_obj.size()) print(queue_obj.dequeue()) print(queue_obj.dequeue()) print(queue_obj.dequeue())
队列的实际用途
所有和时间有关的操作都和队列有关
多个函数的调用
当有多个函数调用时,按照“先调用后返回”的原则,函数之间的信息传递和控制转移必须借助栈来实现,即系统将整个程序运行时所需要的数据空间安排在一个栈中,每当调用一个函数时,就在栈顶分配一个存储区,进行压栈操作,每当一个函数退出时,就释放他的存储区,即进行出栈操作,当前运行的函数永远在栈顶的位置
递归
一个函数自己或者间接调用自己
递归的应用
树和森林就是以递归的方式定义的
树和图的算范就是以递归的方式实现的
很多数学公式就是以递归的方式实现的(斐波那楔序列)
2.4 小结
数据结构:
从狭义的方面讲:
- 数据结构就是为了研究数据的存储问题
- 数据结构的存储包含两个方面:个体的存储 + 个体关系的存储
从广义方面来讲:
- 数据结构既包含对数据的存储,也包含对数据的操作
- 对存储数据的操作就是算法
算法
从狭义的方面讲:
- 算法是和数据的存储方式有关的
从广义的方面讲:
- 算法是和数据的存储方式无关,这就是泛型的思想
3 非线性结构
3.1 树
3.1.1 树的定义
我们可以简单的认为:
- 树有且仅有一个根节点
- 有若干个互不相交的子树,这些子树本身也是一颗树
通俗的定义:
1.树就是由节点和边组成的
2.每一个节点只能有一个父节点,但可以有多个子节点。但有一个节点例外,该节点没有父节点,此节点就称为根节点
3.1.2 树相关的专业术语
- 节点
- 父节点
- 子节点
- 子孙
- 堂兄弟
- 兄弟
- 深度
- 从根节点到最底层节点的层数被称为深度,根节点是第一层
- 叶子节点
- 没有子节点的节点
- 度
- 子节点的个数
- 一般树
- 任意一个节点的子节点的个数不受限制
- 二叉树
- 定义:任意一个节点的子节点的个数最多是两个,且子节点的位置不可更改
- 满二叉树
- 定义:在不增加层数的前提下,无法再多添加一个节点的二叉树
- 完全二叉树
- 定义:只是删除了满二叉树最底层最右边连续的若干个节点
- 一般二叉树
- 满二叉树
- 定义:任意一个节点的子节点的个数最多是两个,且子节点的位置不可更改
- 森林
- n个互不相交的数的集合

3.1.4 树的操作
如何把一个非线性结构的数据转换成一个线性结构的数据存储起来?
一般树的存储
1.双亲表示法(求父节点方便)
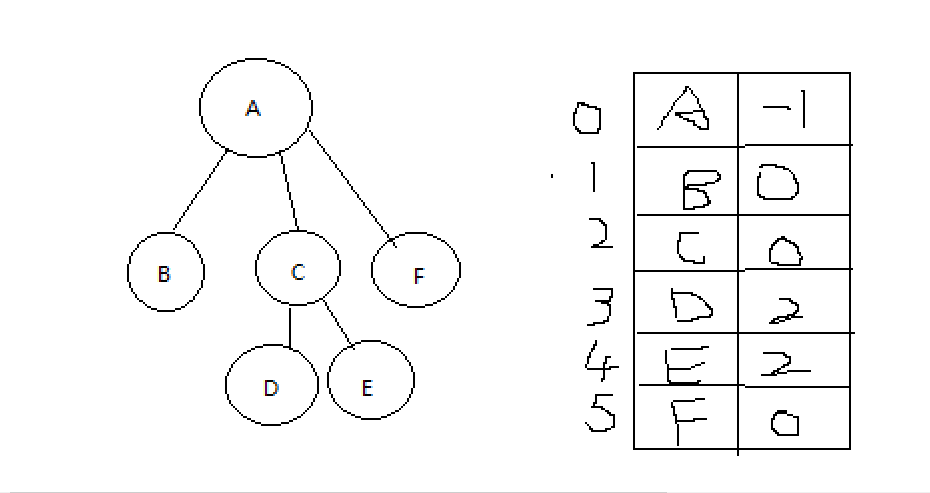
2.孩子表示法(求孩子方便)
3.双亲孩子表示法(求孩子和父亲都很方便)
4.二叉树表示法(即把一般树转换为二叉树,按照二叉树的方法存储)
具体的方法,设法保证
1.左指针域指向它的第一个孩子
2.右指针域指向它的下一个兄弟
二叉树操作
连续存储 (完全二叉树,数组方式进行存储)
优点:查找某个节点的父节点和子节点非常的快
缺点:耗用内存空间过大
转化的方法:先序 中序 后序
链式存储 (链表存储)
data区域 左孩子区域 右孩子区域
森林的操作
把所有的树转化成二叉树,方法同一般树的转化
3.1.5 二叉树的具体操作
1.二叉树的先序遍历[先访问根节点]
先访问根节点
再先序遍历左子树
最后先序遍历右子树
2.二叉树的中序遍历 [中间访问根节点]
先中序遍历左子树’
再访问根节点
最后中序遍历右子树
3.二叉树的后序遍历 [最后访问根节点]
先后序遍历左子树
再后序遍历右子树
最后访问根节点
已知先序和中序,如何求出后序?
后序:DECBHGFA
例2:
后序:GHDBEIFCA
已知中序和后序,如何求出先序?
先序:ABCDEFGH
3.1.6 树的应用
- 树是数据库中数据组织的一种重要形式
- 操作系统子父进程的关系本身就是一颗树
- 面型对象语言中类的继承关系
4 总结
数据结构研究的就是数据的存储和数据的操作的一门学问
数据的存储又分为两个部分:
- 个体的存储
- 个体关系的存储
从某个角度而言,数据存储最核心的就是个体关系如何进行存储
个体的存储可以忽略不计
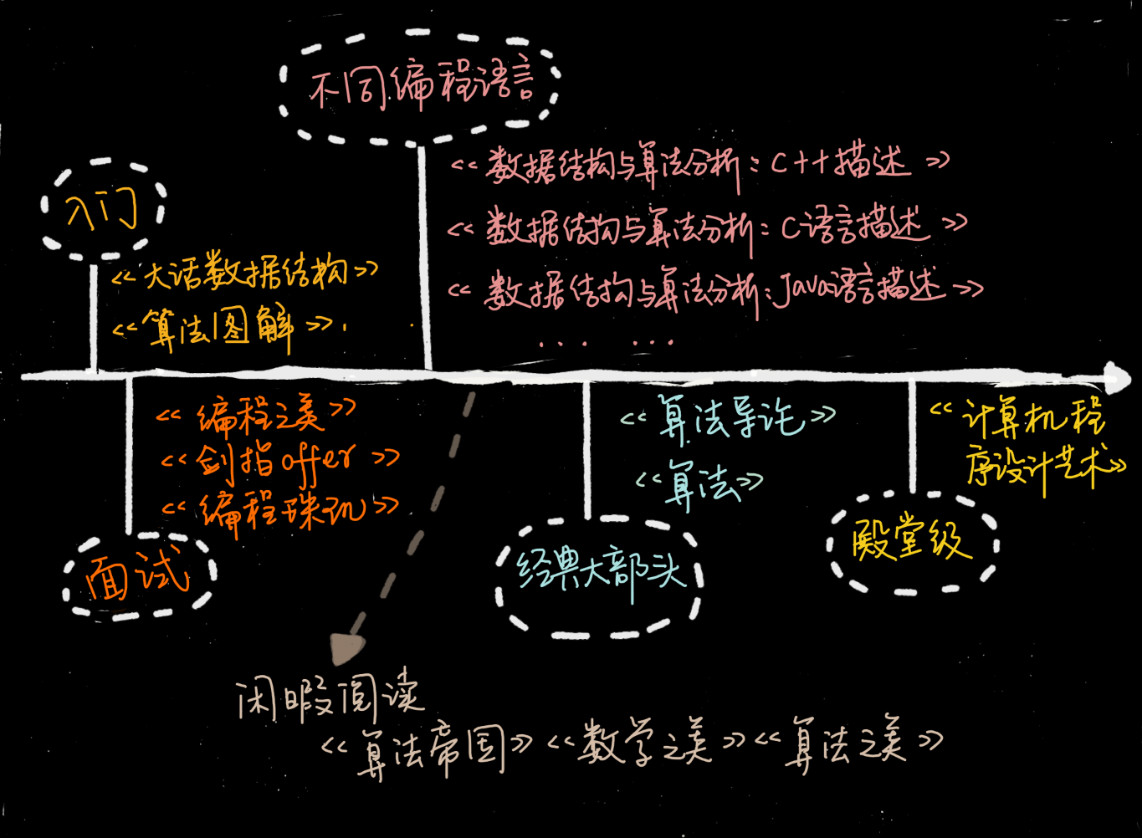
5 数据结构与算法学习的相关书籍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号